Anthropic Mythos AI Unbefugter Zugang: Wie eine Discord-Gruppe das 'zu gefährliche' Cybersicherheitsmodell geknackt hat

Wichtigste Erkenntnisse
- Eine kleine Discord-Gruppe erhielt am selben Tag Zugang zu Anthropics eingeschränktem Mythos (Claude Mythos Preview), an dem es für begrenzte Tests im Rahmen von Project Glasswing angekündigt wurde.
- Der Zugang basierte auf den legitimen Anmeldedaten eines Auftragnehmers von Drittanbietern in Kombination mit dem Erraten von Endpunkt-URLs anhand von Mustern, die beim Mercor-Datenleck veröffentlicht wurden – nicht auf ausgeklügelter Modellhacking.
- Die Gruppe nutzte das Modell für harmlose Aufgaben wie den Aufbau einfacher Websites und vermied bewusst Cybersecurity-Prompts, um der Entdeckung zu entgehen.
- Der Vorfall verdeutlicht, dass KI-Sicherheitsrisiken oft von betrieblichen, Lieferketten- und menschlichen Faktoren ausgehen, nicht allein von den Kernfähigkeiten des Modells.
- Anthropic untersucht aktiv den unbefugten Zugang über eine seiner Umgebungen von Drittanbieter-Lieferanten.
Was ist Anthropics KI-Modell Mythos?
Anthropic entwickelte Mythos als ein hochmodernes KI-Modell, das auf Cybersicherheitsaufgaben spezialisiert ist. Laut dem Unternehmen zeigt es beispiellose Fähigkeiten bei der Identifizierung und Ausnutzung von Zero-Day-Schwachstellen in wichtigen Betriebssystemen und Webbrowsern.
Benchmarks und interne Tests sollen gezeigt haben, dass Mythos Tausende potenzieller Exploits erzeugt, wo frühere Modelle keine produzierten. Dies veranlasste Anthropic, es als zu riskant für eine öffentliche Veröffentlichung einzustufen und den anfänglichen Zugang auf ausgewählte Partner zu beschränken, darunter Apple, Amazon, Cisco und andere Organisationen im Rahmen der Project Glasswing-Initiative.
Das Modell wurde als defensives Werkzeug positioniert, um großen Unternehmen und Regierungen zu helfen, ihre Systeme gegen neu aufkommende KI-gestützte Bedrohungen zu stärken. Sein offensives Potenzial weckte jedoch Bedenken hinsichtlich der Risiken der Verbreitung, sollte es in die Hände von Böswilligen geraten.

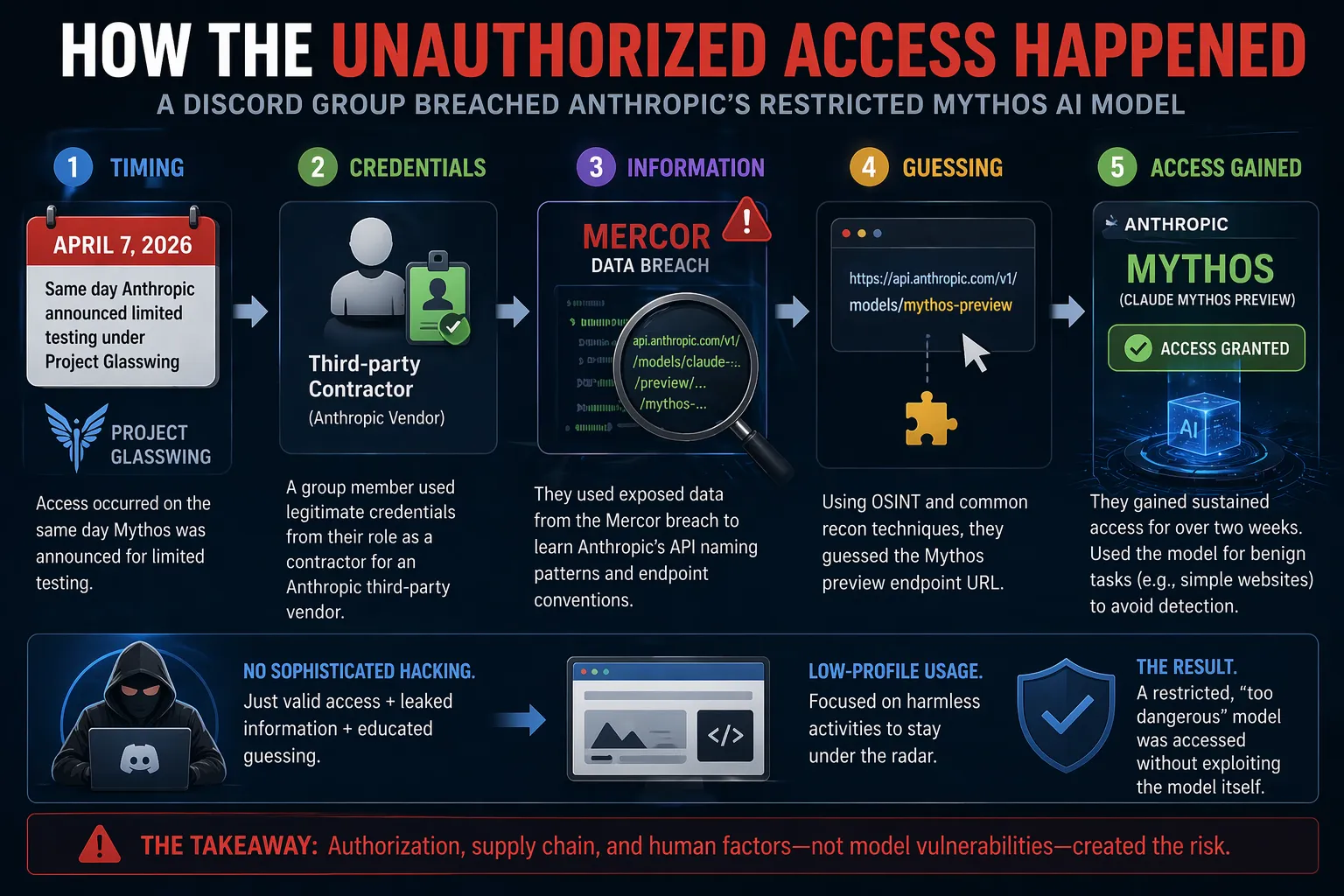
Wie der unbefugte Zugang passierte
Die Analyse von Berichten zeigt, dass die Sicherheitsverletzung bemerkenswert einfach war und nicht ein hochtechnisches Ausnutzen des Modells selbst:
- Zeitpunkt: Der Zugang erfolgte am 7. April 2026 – am gleichen Tag, an dem Anthropic die Verfügbarkeit für limitierte Tests bekannt gab.
- Methode: Mitglieder eines privaten Discord-Channels (mit dem Fokus auf der Überwachung unveröffentlichter KI-Modelle) nutzten:
- Legitime Zugangsdaten eines Gruppenmitglieds, das als Auftragnehmer für einen Anthropic-Drittlieferanten (involved in model evaluation) arbeitete.
- Kenntnisse der API-Endpunkt-Namenskonventionen von Anthropic, die aus einem aktuellen großflächigen Datenleck beim KI-Startup Mercor abgeleitet wurden.
- Intelligente Schätzungen der Mythos-Vorschau-Endpunkt-URL mit Hilfe von üblichen Internet-Aufklärungsmethoden.
Die Kombination ermöglichte einen kontinuierlichen Zugang für über zwei Wochen. Die Gruppe stellte Screenshots und eine Live-Demonstration Journalisten zur Verfügung, um ihre Behauptungen zu verifizieren.
Beachtlich ist, dass sie Hochrisiko-Cybersicherheits-Prompts vermieden und sich stattdessen für harmlose Aktivitäten wie das Generieren einfacher Websites entschieden. Diese zurückhaltende Vorgehensweise half ihnen wahrscheinlich, länger unauffällig zu bleiben.

Warum dieser Einbruch wichtig ist: Mehr als nur Modellgewichte
Das Feedback der Community und Diskussionen von Experten zeigen, dass dieses Ereignis eine kritische Wahrheit in der KI-Sicherheit verdeutlicht: die schwächsten Verbindungen sind oft prozedural und menschenzentriert, nicht technische Modellschutzmechanismen.
Benchmarks für Mythos fokussierten auf seine Cyberfähigkeiten, doch die realweltliche Gefährdung kam von:
- Lieferketten-Schwachstellen: Drittauftragnehmer und Lieferanten mit legitimen Zugang.
- Vorhersagbare Infrastruktur-Muster: Wiederwendbare Namenskonventionen für Modellendpunkte.
- Verstärkung von Datenlecks: Informationen von nicht verwandten Lecks (z.B. Mercor), die Aufklärung ermöglichen.
- Vertrauensannahmen: Übermäßige Abhängigkeit von kontrollierten Umgebungen ohne ausreichende Isolation oder Überwachung des Lieferantenzugangs.
Vergleiche mit vergangenen KI-Vorfällen zeigen ein Muster – viele "gefährliche" Modelle haben Herausforderungen der Abschirmung nicht von gegnerischen Attacken auf Gewichte, sondern von operationellen Mängeln. Dieser Fall ähnelt dem Verlassen einer hochmodernen Waffe in einem geschlossenen Raum während die Seitentür des Gebäudes offen bleibt.
Randfälle umfassen:
- Gemeinsame Zugangsdaten zwischen Auftragnehmern oder Partner.
- Public breadcrumbs (GitHub, Dokumentationsmuster) helfen bei der URL-Vorhersage.
- Überwachungsblindstellen wenn Nutzung unter bestimmten Risikogrenzen bleibt.
Häufige Fallstricke bei eingeschränktem KI-Einsatz
Die Analyse ähnlicher KI-Veröffentlichungen mit hohen Risiken zeigt wiederkehrende Probleme:
- Überbetonung der Modellausrichtung bei gleichzeitiger Unterinvestition in Laufzeit-Zugriffskontrollen und Überwachung.
- Onboarding von Anbietern und Partnern ohne detaillierte, zeitlich begrenzte Berechtigungen oder Anomalieerkennung.
- Vorhersehbare Namensgebung und Endpunkte, die die Aufklärung für informierte Insider vereinfachen.
- Fehlende Segmentierung der Umgebungen zwischen internem Testen, Anbieterbewertung und eingeschränktem Partnerzugang.
Erweiterte Abwehrstrategien, die in Cybersicherheitskreisen diskutiert werden, umfassen:
- Dynamische, kurzlebige Endpunkte mit strenger Authentifizierung.
- Verhaltensüberwachung, die selbst harmlose Nutzungsmuster aus unerwarteten Quellen kennzeichnet.
- Regelmäßige Rotation von Namenskonventionen und Berechtigungsumfängen.
- Audits der Lieferkettensicherheit mit Fokus auf Zugangswege von Auftragnehmern.
Implikationen für KI-Sicherheit und Cybersicherheit
Der Mythos-Vorfall wirft weitere Fragen zur Steuerung leistungsstarker dual-use KI-Technologien auf. Obwohl die Gruppe das Modell nicht als Waffe einsetzte, zeigt die leichte Zugänglichkeit, wie schnell eingeschränkte Fähigkeiten sich über informelle Netzwerke verbreiten können.
Finanzinstitute, Regierungen und Unternehmen, die Mythos testen, müssen nun nicht nur den defensiven Wert des Modells neu bewerten, sondern auch die Risiken ähnlicher Expositionsvektoren. Regulierungsbehörden beobachten die Entwicklungen bereits, wobei Diskussionen in Foren wie dem Financial Stability Board systemische Bedenken hervorheben.
Vergleiche mit anderen KI-Firmen zeigen, dass Anthropic nicht allein dasteht – viele Organisationen ringen mit der Balance zwischen Innovationsgeschwindigkeit und robuster Eindämmung in Cloud-basierten Bereitstellungen.
Fazit
Der unbefugte Zugang zu Anthropics Mythos-Modell dient als zeitgemäße Erinnerung, dass echte KI-Sicherheit weit über Trainingsdaten und Ausrichtungstechniken hinausgeht. Betriebssicherheit, Integrität der Lieferkette und menschliche Faktoren spielen eine ebenso entscheidende Rolle.
Da sich KI-Fähigkeiten in sensiblen Bereichen wie Cybersicherheit weiterentwickeln, müssen Organisationen umfassende Zugriffssteuerung neben der Modellentwicklung priorisieren. Stakeholder in KI, Cybersicherheit und Politik sollten die Untersuchungsergebnisse von Anthropic genau verfolgen und gestärkte Best Practices für eingeschränkte Bereitstellungen in Betracht ziehen.
Für Fachleute, die mit Grenz-KI-Systemen arbeiten, ist die Überprüfung interner Anbietermanagement-, Endpunktsicherheits- und Überwachungsprotokolle ein empfommener erster Schritt, um ähnliche Expositionsrisiken zu reduzieren.
Continue Reading
More articles connected to the same themes, protocols, and tools.

Google investiert bis zu 40 Milliarden Dollar in Anthropic mit 5GW Rechenleistung: Das KI-Wettrüsten tritt in eine neue Ära
Anthropic Mythos AI Unauthorized Access: How a Discord Group Breached the 'Too Dangerous' Cybersecurity Model

How to Access the Fable 5 API: A Developer’s Guide to Claude’s Mythos-Class Model
Referenced Tools
Browse entries that are adjacent to the topics covered in this article.




