Anthropic Mythos AI Unauthorized Access: How a Discord Group Breached the 'Too Dangerous' Cybersecurity Model

Key Takeaways
- A small Discord group gained access to Anthropic's restricted Mythos (Claude Mythos Preview) on the same day it was announced for limited testing under Project Glasswing.
- Access relied on a third-party contractor's legitimate credentials combined with endpoint URL guessing based on patterns leaked in the Mercor data breach — not sophisticated model hacking.
- The group used the model for benign tasks like building simple websites, deliberately avoiding cybersecurity prompts to evade detection.
- The incident highlights that AI safety risks often stem from operational, supply chain, and human factors rather than the model's core capabilities alone.
- Anthropic is actively investigating the unauthorized access through one of its third-party vendor environments.
What Is Anthropic's Mythos AI Model?
Anthropic developed Mythos as a highly advanced AI model specialized in cybersecurity tasks. According to the company, it demonstrates unprecedented capabilities in identifying and exploiting zero-day vulnerabilities across major operating systems and web browsers.
Benchmarks and internal testing reportedly showed Mythos generating thousands of potential exploits where previous models produced none. This led Anthropic to classify it as too risky for public release, limiting initial access to select partners including Apple, Amazon, Cisco, and other organizations under the Project Glasswing initiative.
The model was positioned as a defensive tool to help large enterprises and governments strengthen their systems against emerging AI-powered threats. However, its offensive potential raised alarms about proliferation risks if it fell into malicious hands.

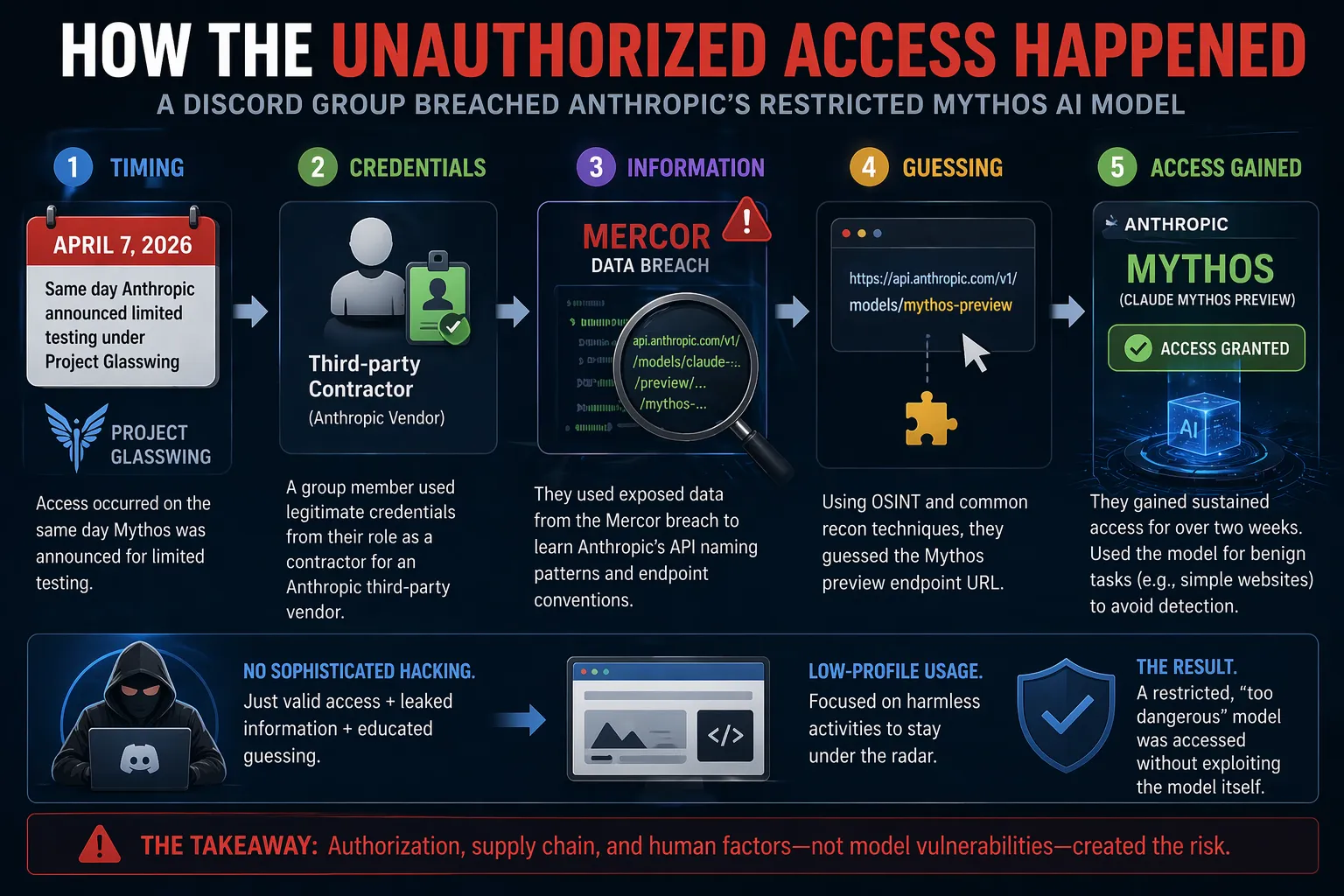
How the Unauthorized Access Happened
Analysis of reports indicates the breach was remarkably straightforward rather than a high-tech exploit of the model itself:
- Timing: Access occurred on April 7, 2026 — the same day Anthropic announced limited testing availability.
- Method: Members of a private Discord channel (focused on tracking unreleased AI models) used:
- Legitimate credentials from a group member who worked as a contractor for an Anthropic third-party vendor (involved in model evaluation).
- Knowledge of Anthropic's API endpoint naming conventions, derived from a recent large-scale data breach at AI startup Mercor.
- Educated guessing of the Mythos preview endpoint URL using common internet reconnaissance techniques.
The combination allowed sustained access for over two weeks. The group provided screenshots and a live demonstration to journalists to verify their claims.
Notably, they avoided running high-risk cybersecurity prompts, opting instead for harmless activities such as generating simple websites. This low-profile approach likely helped them remain undetected longer.

Why This Breach Matters: Beyond Model Weights
Community feedback and expert discussions suggest this incident underscores a critical truth in AI safety: the weakest links are often procedural and human-centric rather than technical model safeguards.
Benchmarks of Mythos focused on its cyber capabilities, yet the real-world exposure stemmed from:
- Supply chain vulnerabilities: Third-party contractors and vendors with legitimate access.
- Predictable infrastructure patterns: Reusable naming conventions for model endpoints.
- Data leakage amplification: Information from unrelated breaches (e.g., Mercor) enabling reconnaissance.
- Trust assumptions: Over-reliance on controlled environments without sufficient isolation or monitoring of vendor access.
Comparisons with past AI incidents show a pattern — many "dangerous" models face containment challenges not from adversarial attacks on weights, but from operational gaps. This case resembles leaving an advanced weapon in a locked room while the building's side door remains open.
Edge cases include:
- Shared credentials among contractors or partners.
- Public breadcrumbs (GitHub, documentation patterns) aiding URL prediction.
- Monitoring blind spots when usage stays below certain risk thresholds.
Common Pitfalls in Restricted AI Deployment
Analysis of similar high-stakes AI releases reveals recurring issues:
- Overemphasis on model alignment while underinvesting in runtime access controls and auditing.
- Vendor and partner onboarding without granular, time-limited permissions or anomaly detection.
- Naming and endpoint predictability that simplifies reconnaissance for knowledgeable insiders.
- Failure to segment environments between internal testing, vendor evaluation, and limited partner access.
Advanced mitigation strategies discussed in cybersecurity circles include:
- Dynamic, ephemeral endpoints with strict authentication.
- Behavioral monitoring that flags even benign usage patterns from unexpected sources.
- Regular rotation of naming conventions and credential scopes.
- Supply chain security audits focusing on contractor access paths.
Implications for AI Safety and Cybersecurity
The Mythos incident raises broader questions about governing powerful dual-use AI technologies. While the group did not weaponize the model, the ease of access demonstrates how quickly restricted capabilities can spread through informal networks.
Financial institutions, governments, and enterprises testing Mythos must now reassess not only the model's defensive value but also the risks of similar exposure vectors. Regulators are already monitoring developments, with discussions in forums like the Financial Stability Board highlighting systemic concerns.
Comparisons with other AI firms show that Anthropic is not alone — many organizations grapple with balancing innovation speed against robust containment in cloud-based deployments.
Conclusion
The unauthorized access to Anthropic's Mythos model serves as a timely reminder that true AI safety extends far beyond training data and alignment techniques. Operational security, supply chain integrity, and human factors play equally decisive roles.
As AI capabilities in sensitive domains like cybersecurity continue to advance, organizations must prioritize comprehensive access governance alongside model development. Stakeholders in AI, cybersecurity, and policy should closely monitor Anthropic's investigation outcomes and consider strengthened best practices for restricted deployments.
For professionals working with frontier AI systems, reviewing internal vendor management, endpoint security, and monitoring protocols is a recommended immediate step to reduce similar exposure risks.
Continue Reading
More articles connected to the same themes, protocols, and tools.



Referenced Tools
Browse entries that are adjacent to the topics covered in this article.




