Anthropic Mythos AIへの不正アクセス:Discordグループが「危険すぎる」サイバーセキュリティモデルをいかに突破したか

主な要点
- 限定的なテストとしてプロジェクト・グラスウィングのもと発表された同日、小さなDiscordグループがAnthropicの限定公開モデル 「Mythos」(Claude Mythos Preview)へのアクセスを獲得した。
- アクセスは、第三者契約者の正規の資格情報と、Mercorデータ流出で漏洩したパターンに基づくエンドポイントURLの推測に依存したもので、高度なモデルハッキングではなかった。
- グループは検知を回避するため、サイバーセキュリティ関連のプロンプトを意図的に避け、簡単なウェブサイト構築などの無害なタスクにモデルを使用した。
- この事例は、AIセーフティリスクがモデルの中核的能力だけでなく、運用、サプライチェーン、人的要因に起因することが多いことを浮き彫りにしている。
- Anthropicは、第三者ベンダー環境の一つを通じた不正アクセスを積極的に調査中である。
AnthropicのMythos AIモデルとは?
Anthropicが開発した 「Mythos」 は、サイバーセキュリティタスクに特化した高度に先進的なAIモデルである。同社によると、主要なオペレーティングシステムやウェブブラウザにおけるゼロデイ脆弱性の特定および悪用において、前例のない能力を発揮するという。
ベンチマークおよび内部テストでは、従来のモデルでは全く生成されなかった潜在的なエクスプロイト(悪用コード)をMythosが数千個生成したと報告されており、これが一般公開にはリスクが高すぎるとAnthropicが判断する要因となった。初期アクセスは、プロジェクト・グラスウィングの下で、Apple、Amazon、Ciscoなどの選ばれたパートナー組織に限定されている。
このモデルは、大企業や政府が新興のAI活用型脅威に対抗してシステムを強化するための防御ツールとして位置づけられていた。しかし、その攻撃的可能性は、悪意のある者に渡った場合の拡散リスクについて懸念を生じさせた。

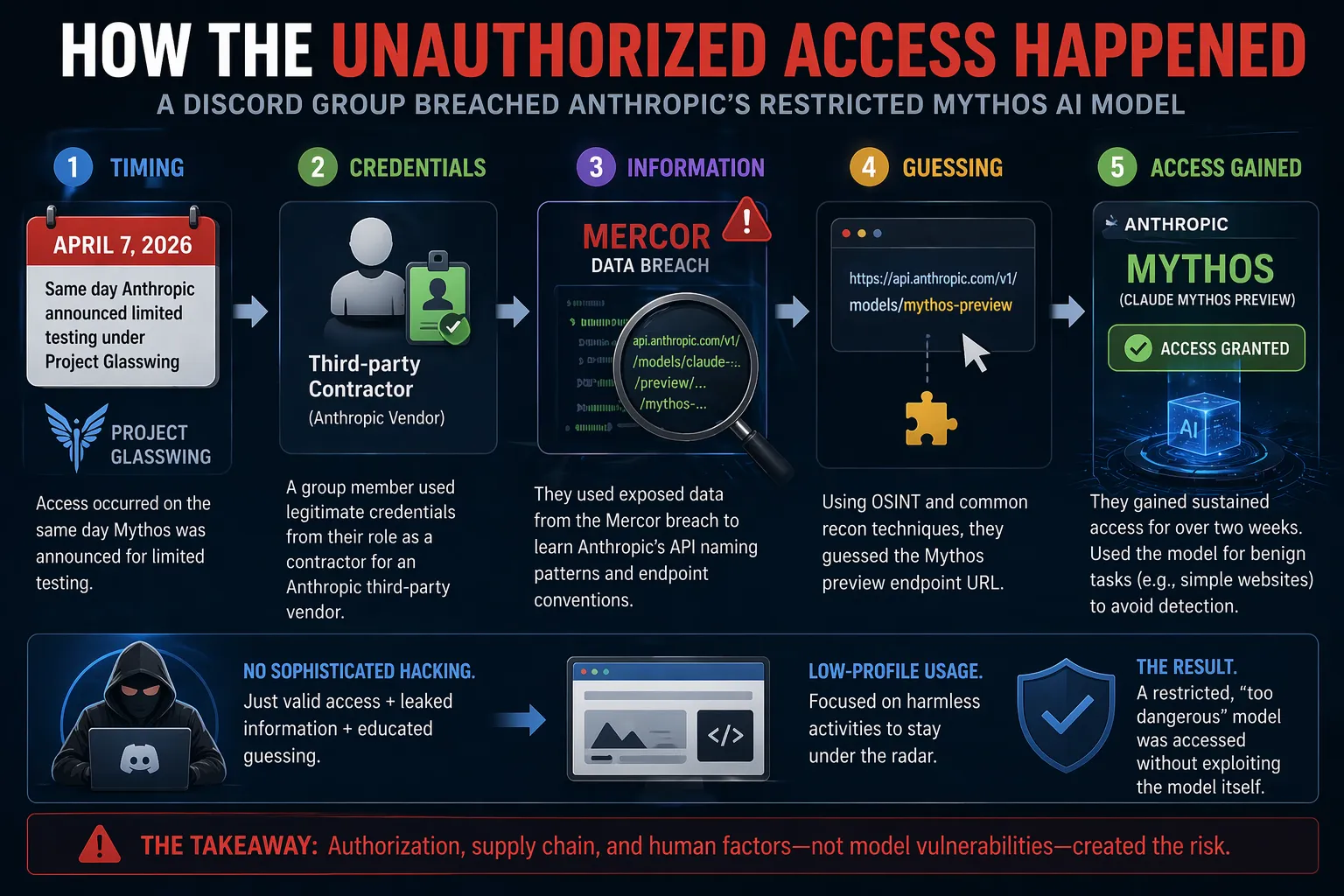
不正アクセスが発生した経緯
報告書の分析によると、この侵害は高度な技術によるモデル自体のエクスプロイトではなく、驚くほど単純な手法で行われました:
- タイミング: 2026年4月7日にアクセスが発生しました — これはAnthropicが限定テストの提供を発表した同日です。
- 方法: 非公開Discordチャンネルのメンバー(未公開AIモデルの追跡に焦点を当てたグループ)が以下の手段を用いました:
- Anthropicの第三者ベンダー(モデル評価に関与)の契約社員として働くグループメンバーの正当な資格情報。
- AIスタートアップMercorでの最近の大規模データ侵害から得た、AnthropicのAPIエンドポイント命名規則に関する知識。
- 一般的なインターネット偵察技術を用いた、MythosプレビューエンドポイントURLの推定。
これらの組み合わせにより、2週間以上継続的なアクセスが可能になりました。グループは自身の主張を裏付けるため、記者にスクリーンショットとライブデモを提供しました。
注目すべき点は、高リスクのサイバーセキュリティプロンプトを実行することを避け、代わりに単純なWebサイト生成などの無害な活動を行ったことです。この低姿勢のアプローチが、長時間検知されずにいることに役立った可能性があります。

この侵害が重要である理由:モデルの重みを超えた影響
コミュニティのフィードバックと専門家の議論は、この事件がAI安全性における重要な真実を強調していることを示唆しています:最も脆弱なポイントは、技術的なモデル保護策ではなく、プロセスや人に関わる部分であることが多い。
Mythosのベンチマークはそのサイバー能力に焦点を当てていましたが、現実世界での曝露は以下の要因から生じました:
- サプライチェーンの脆弱性: 正当なアクセス権を持つ第三者契約社員やベンダー。
- 予測可能なインフラストラクチャパターン: モデルエンドポイントの再利用可能な命名規則。
- データ漏洩の拡大: 無関係な侵害(例:Mercor)からの情報が偵察を可能にする。
- 信頼の前提: ベンダーのアクセスに対する十分な隔離や監視なしに、制御された環境への過度な依存。
過去のAI事件との比較は、多くの「危険な」モデルが重みに対する敵対的攻撃ではなく、運用上のギャップから封じ込めの課題に直面するというパターンを示しています。このケースは、高度な武器を鍵がかかった部屋に置きながら、建物の側口が開いているような状態に似ています。
エッジケースには以下が含まれます:
- 契約社員やパートナー間での共有資格情報。
- GitHubやドキュメントパターンなどの公開された痕跡がURL予測を支援すること。
- 使用が特定のリスク閾値を下回る場合の監視の盲点。
AI制限公開における共通の落とし穴
類似のハイリスクAI公開を分析すると、繰り返し発生する課題が明らかです:
- モデルの適合性への過度な重視と、ランタイムのアクセス制御や監査への投資不足。
- ベンダーやパートナーのオンボーディングにおける、詳細で期間限定の権限や異常検知の欠如。
- 命名規則とエンドポイントの予測可能性が、知識のある内部関係者の偵察活動を容易にする。
- 内部テスト、ベンダー評価、限定パートナーアクセスの間での環境分離の失敗。
セキュリティ専門家の間で議論される高度な対策策には以下が含まれます:
- 厳格な認証を伴う動的・短命のエンドポイント。
- 予期しない送信元からの、良性の使用パターンも警告する行動監視。
- 命名規則と権限スコープの定期的なローテーション。
- 契約者のアクセス経路に焦点を置くサプライチェーンセキュリティ監査。
AI安全性とサイバーセキュリティへの影響
Mythos事件は、強力な二重用途AI技術の管理に関するより広範な疑問を提起しています。グループはモデルを武器化しませんでしたが、アクセスの容易さは、制限された能力が非公式のネットワークを通じて急速に拡散する可能性を示しています。
金融機関、政府、およびMythosをテストしている企業は、モデルの防御的価値だけでなく、類似の暴露ベクトルのリスクも再評価する必要があります。規制当局はすでに状況を監視し、金融安定理事会などのフォーラムではシステム全体への懸念が議論されています。
他のAI企業との比較は、Anthropicが単独ではないことを示しています――多くの組織が、クラウドベースの展開における革新速度と堅牢な封じ込めのバランス調整に苦心しています。
結論
AnthropicのMythosモデルへの不正アクセスは、真のAI安全性はトレーニングデータや適合技術を遥かに超える範囲に広がっていることを、時宜を得た警告として示しています。運用上のセキュリティ、サプライチェーンの完全性、人的要素が同じく決定的な役割を果たします。
サイバーセキュリティのような敏感な領域でのAI能力が進歩し続ける中、組織はモデル開発と並行して包括的なアクセス管理を優先する必要があります。AI、サイバーセキュリティ、政策分野の関係者は、Anthropicの調査結果を注視し、制限公開における強化されたベストプラクティスを考慮するべきです。
最先端AIシステムを扱う専門家にとって、内部ベンダー管理、エンドポイントセキュリティ、監視プロトコルのレビューは、類似の暴露リスクを減らすための推奨される即時のステップです。
Continue Reading
More articles connected to the same themes, protocols, and tools.


Referenced Tools
Browse entries that are adjacent to the topics covered in this article.





