Acesso Não Autorizado à IA Mythos da Anthropic: Como um Grupo do Discord Violou o Modelo de Cibersegurança 'Muito Perigoso'

Pontos-Chave
- Um pequeno grupo do Discord obteve acesso ao restrito Mythos da Anthropic (Claude Mythos Preview) no mesmo dia em que foi anunciado para testes limitados sob o Projeto Glasswing.
- O acesso foi obtido utilizando credenciais legítimas de um contratante terceirizado, combinadas com a adivinhação de URLs de endpoint baseada em padrões vazados na violação de dados do Mercor — não por meio de hacking sofisticado do modelo.
- O grupo usou o modelo para tarefas benignas, como construir sites simples, evitando deliberadamente prompts de cibersegurança para não ser detectado.
- O incidente destaca que os riscos de segurança da IA frequentemente surgem de fatores operacionais, da cadeia de suprimentos e humanos, e não apenas das capacidades centrais do modelo.
- A Anthropic está investigando ativamente o acesso não autorizado por meio de um dos ambientes de seus fornecedores terceirizados.
O Que É o Modelo de IA Mythos da Anthropic?
A Anthropic desenvolveu o Mythos como um modelo de IA altamente avançado especializado em tarefas de cibersegurança. De acordo com a empresa, ele demonstra capacidades sem precedentes na identificação e exploração de vulnerabilidades de dia zero em sistemas operacionais e navegadores principais.
Testes de benchmark e internos supostamente mostraram o Mythos gerando milhares de possíveis exploits onde modelos anteriores não produziram nenhum. Isso levou a Anthropic a classificá-lo como arriscado demais para lançamento público, limitando o acesso inicial a parceiros selecionados, incluindo Apple, Amazon, Cisco e outras organizações sob a iniciativa Project Glasswing.
O modelo foi posicionado como uma ferramenta defensiva para ajudar grandes empresas e governos a fortalecerem seus sistemas contra ameaças emergentes impulsionadas por IA. No entanto, seu potencial ofensivo levantou preocupações sobre riscos de proliferação caso caísse em mãos mal-intencionadas.

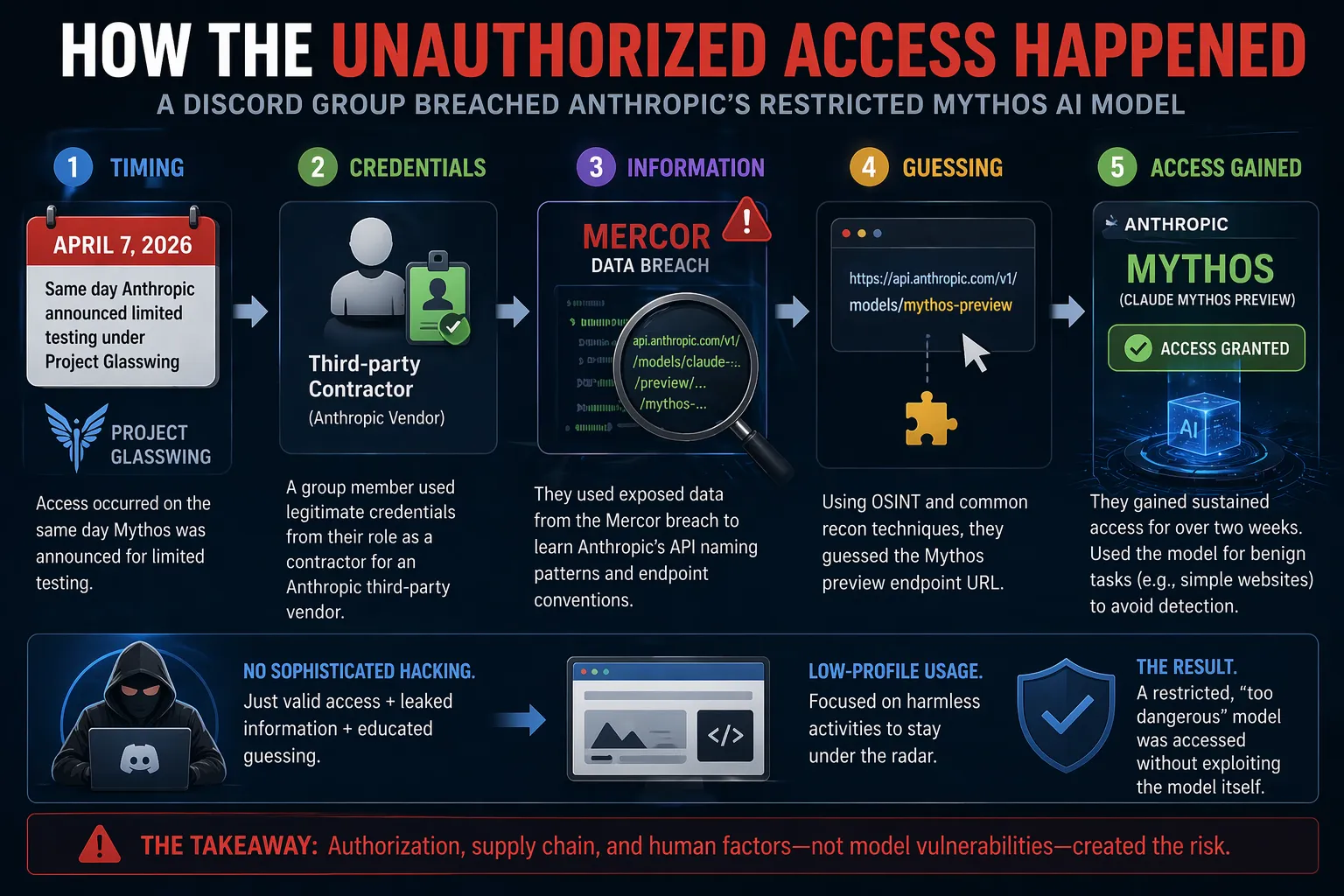
Como Ocorreu o Acesso Não Autorizado
A análise dos relatórios indica que a violação foi notavelmente simples, em vez de uma exploração de alta tecnologia do próprio modelo:
- Momento: O acesso ocorreu em 7 de abril de 2026 — no mesmo dia em que a Anthropic anunciou a disponibilidade de testes limitados.
- Método: Membros de um canal privado do Discord (focado em rastrear modelos de IA não lançados) usaram:
- Credenciais legítimas de um membro do grupo que trabalhava como contratado para um fornecedor terceirizado da Anthropic (envolvido na avaliação do modelo).
- Conhecimento das convenções de nomenclatura dos endpoints da API da Anthropic, derivadas de uma recente violação de dados em larga escala na startup de IA Mercor.
- Suposições fundamentadas da URL do endpoint de prévia do Mythos, utilizando técnicas comuns de reconhecimento na internet.
A combinação permitiu acesso sustentado por mais de duas semanas. O grupo forneceu capturas de tela e uma demonstração ao vivo para jornalistas para verificar suas alegações.
Notavelmente, eles evitaram executar prompts de alto risco em cibersegurança, optando em vez disso por atividades inofensivas, como gerar sites simples. Essa abordagem discreta provavelmente os ajudou a permanecer indetectados por mais tempo.

Por Que Esta Violação Importa: Além dos Pesos do Modelo
O feedback da comunidade e as discussões de especialistas sugerem que este incidente ressalta uma verdade crítica em segurança de IA: os elos mais fracos são frequentemente procedimentais e centrados no ser humano, em vez de salvaguardas técnicas do modelo.
Os benchmarks do Mythos focaram em suas capacidades cibernéticas, mas a exposição no mundo real resultou de:
- Vulnerabilidades da cadeia de suprimentos: Contratados e fornecedores terceirizados com acesso legítimo.
- Padrões de infraestrutura previsíveis: Convenções de nomenclatura reutilizáveis para endpoints de modelo.
- Amplificação de vazamento de dados: Informações de violações não relacionadas (por exemplo, Mercor) possibilitando reconhecimento.
- Suposições de confiança: Excesso de dependência em ambientes controlados sem isolamento ou monitoramento suficientes do acesso de fornecedores.
Comparações com incidentes anteriores de IA mostram um padrão — muitos modelos "perigosos" enfrentam desafios de contenção não devido a ataques adversariais aos pesos, mas a lacunas operacionais. Este caso lembra deixar uma arma avançada em uma sala trancada enquanto a porta lateral do prédio permanece aberta.
Casos extremos incluem:
- Credenciais compartilhadas entre contratados ou parceiros.
- Migalhas de pão públicas (GitHub, padrões de documentação) auxiliando na previsão de URLs.
- Pontos cegos de monitoramento quando o uso permanece abaixo de certos limiares de risco.
Armadilhas Comuns na Implementação de IA Restrita
A análise de lançamentos de IA semelhantes de alto risco revela problemas recorrentes:
- Ênfase excessiva no alinhamento do modelo enquanto subinveste em controles de acesso em tempo de execução e auditorias.
- Integração de fornecedores e parceiros sem permissões granulares, com limite de tempo ou detecção de anomalias.
- Previsibilidade na nomenclatura e endpoints que simplifica a reconhecimento para insiders experientes.
- Falha em segmentar ambientes entre testes internos, avaliação de fornecedores e acesso limitado a parceiros.
Estratégias avançadas de mitigação discutidas nos círculos de cibersegurança incluem:
- Endpoints dinâmicos e efêmeros com autenticação estrita.
- Monitoramento comportamental que sinaliza padrões de uso até mesmo benignos provenientes de fontes inesperadas.
- Rotação regular das convenções de nomenclatura e escopos de credenciais.
- Auditorias de segurança da cadeia de suprimentos focadas em caminhos de acesso de contratados.
Implicações para Segurança de IA e Cibersegurança
O incidente do Mythos levanta questões mais amplas sobre a governança de poderosas tecnologias de IA de uso duplo. Embora o grupo não tenha armado o modelo, a facilidade de acesso demonstra como capacidades restritas podem se espalhar rapidamente por redes informais.
Instituições financeiras, governos e empresas testando o Mythos devem agora reavaliar não apenas o valor defensivo do modelo, mas também os riscos de vetores de exposição semelhantes. Reguladores já estão monitorando os desdobramentos, com discussões em fóruns como o Conselho de Estabilidade Financeira destacando preocupações sistêmicas.
Comparações com outras empresas de IA mostram que a Anthropic não está sozinha — muitas organizações lutam para equilibrar a velocidade de inovação com a contenção robusta em implementações baseadas em nuvem.
Conclusão
O acesso não autorizado ao modelo Mythos da Anthropic serve como um lembrete oportuno de que a verdadeira segurança da IA vai muito além de dados de treinamento e técnicas de alinhamento. Segurança operacional, integridade da cadeia de suprimentos e fatores humanos desempenham papéis igualmente decisivos.
À medida que as capacidades da IA em domínios sensíveis como a cibersegurança continuam a avançar, as organizações devem priorizar uma governança de acesso abrangente, juntamente com o desenvolvimento de modelos. Partes interessadas em IA, cibersegurança e políticas públicas devem acompanhar de perto os resultados da investigação da Anthropic e considerar práticas recomendadas reforçadas para implementações restritas.
Para profissionais que trabalham com sistemas de IA de fronteira, revisar a gestão interna de fornecedores, a segurança de endpoints e os protocolos de monitoramento é uma etapa imediata recomendada para reduzir riscos de exposição semelhantes.
Continue Reading
More articles connected to the same themes, protocols, and tools.
Anthropic Mythos AI Unauthorized Access: How a Discord Group Breached the 'Too Dangerous' Cybersecurity Model

How to Access the Fable 5 API: A Developer’s Guide to Claude’s Mythos-Class Model

Google Investe Até US$ 40 Bilhões na Anthropic com Suporte de 5GW de Computação: Corrida Armamentista de IA Entra em Nova Era
Referenced Tools
Browse entries that are adjacent to the topics covered in this article.





